-
ElasticSearch - 색인과정 한눈에 보기ElasticSearch 2024. 9. 23. 22:18반응형
ElasticSearch - 색인과정

Elasticsearch에서는 노드가 클러스터 안에서 데이터를 저장하고 처리하는 독립적인 서버입니다. 아래의 그림에서는 3개의 데이터 노드가 있는데, 이는 고가용성(High Availability)과 부하 분산(Load Balancing)을 위한 구성이기 때문입니다. 클러스터는 데이터의 일부를 여러 노드에 분산해서 저장함으로써, 하나의 노드가 다운되더라도 데이터를 복구할 수 있습니다. 아래의 환경을 기본적인 환경이라고 가정하고 색인과정을 살펴보기전에 기본 개념에 대해 다시한번 알아보겠습니다.
데이터 노드 = 서버
서버 또는 가상 머신에 Elasticsearch가 설치되면, 그 서버는 Elasticsearch 클러스터의 하나의 노드로 동작합니다. 이 노드가 데이터 노드 역할을 수행할 경우, 데이터를 저장하고 검색하는 작업을 처리하게 됩니다.
따라서, 데이터 노드는 실제 물리적인 서버 또는 클라우드 인프라 내 가상 머신일 수 있으며, 이들 서버가 모여 Elasticsearch 클러스터를 구성합니다.클러스터와 노드의 관계:
클러스터는 여러 개의 노드로 구성됩니다. 노드 하나가 서버 하나에 해당하며, 여러 개의 노드가 함께 하나의 Elasticsearch 클러스터를 구성하게 됩니다.
데이터 노드 외에도, 마스터 노드나 코디네이팅 노드 등의 역할을 부여할 수 있으며, 각각의 역할에 따라 클러스터 내에서 다른 작업을 수행합니다.초록색 네모의 경우 데이터 노드를 의미한다. 어떠한 문서가 books라는 라이브러리에 색인이 되는 경우이다.
Books라는 인덱스가 생성이 되고 해당 인덱스의 데이터를 저장할 샤드, 첫번째 데이터 노드에서 프라이머리 샤드, 두번째 데이터노드에 레플리카 샤드가 만들어진다.
첫 번째와 두 번째 데이터 노드에 샤드가 배치되는 이유는 데이터의 안정성 과 내결함성 을 보장하기 위함입니다.
또한 비어있느 노드에 우선 배치가 되기 때문입니다.
여기서 프라이머리 샤드와 레플리카 샤드가 다른 데이터 노드에 존재하는 이유는,데이터 안전성 때문입니다. 만약 하나의 노드에 프라이머리 샤드와 그 레플리카 샤드가 함께 있다가 그 노드가 다운되면, 데이터 복구가 불가능합니다. 이를 방지하기 위해 서로 다른 노드에 프라이머리와 레플리카를 나누어 배치합니다.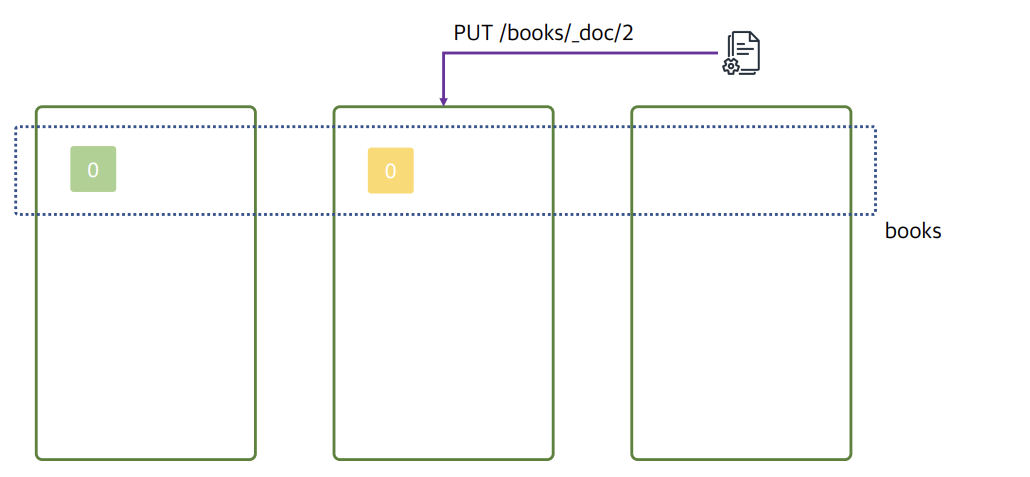
그리고는 2번이라는 id를 가진 해당 문서를 두번째 데이터노드에게 PUT요청을 한다.
number_of_shards, number_of_replicas 의값이 1로 설정되어있기에 세번째 데이터 노드는 사용되지 않는다.
색인 요청이 들어온다면
엘라스틱은 클러스터로 구성되어있기 때문에 어떤 노드에 요청을 해도 동일한 응답을 보장한다.
클러스터는 여러 노드로 구성되어 있기 때문에, Elasticsearch는 내부 라우팅 알고리즘을 사용하여 문서가 저장될 적절한 샤드와 노드를 자동으로 결정합니다.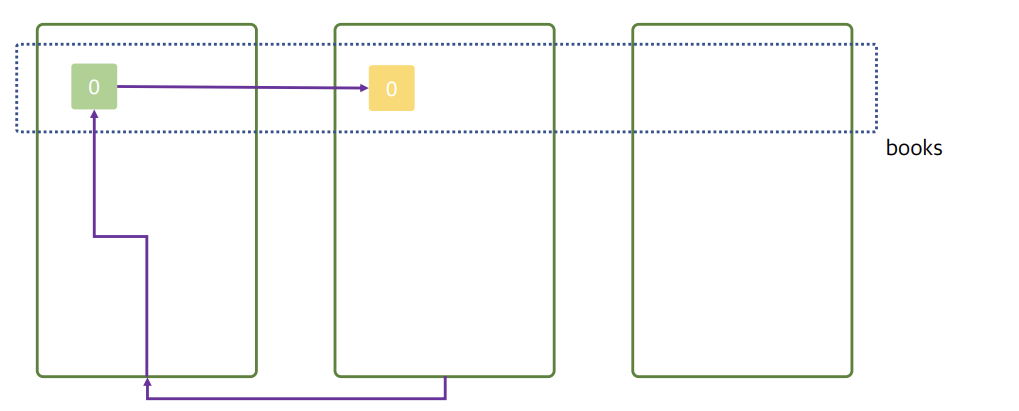
두번째 데이터 노드에게 색인을 요청하였지만 두번째 데이터노드에서는 해당 문서를 저장하기위한 프라이머리 샤드를 가지고 있지 않다. 그렇기 때문에 내부 라우팅 알고리즘에 의하여 자신이 전달받은 문서를 첫번째 노드(프라이머리 샤드)로 전달을 한다. 첫번째 데이터노드는 전달받은 문서를 저장하고 이를 두번째 데이터노드에 있는 레플리카 샤드로 복제한다.

여기서 문제점은 세번째 데이터노드는 아무것도 하지 않고 있다는 것이다.
이러한 상황이 바로 클러스터로서의 이점을 전혀 살리지 못하는 상황이다.그렇기 때문에 적절한 수의 샤드 개수를 설정하는 것이 성능에 큰 영향을 미칩니다.
만약 아래와같이 적용을 시킨다면?
PUT _index_template/base_template { "index_patterns": ["books"], "template": { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } } }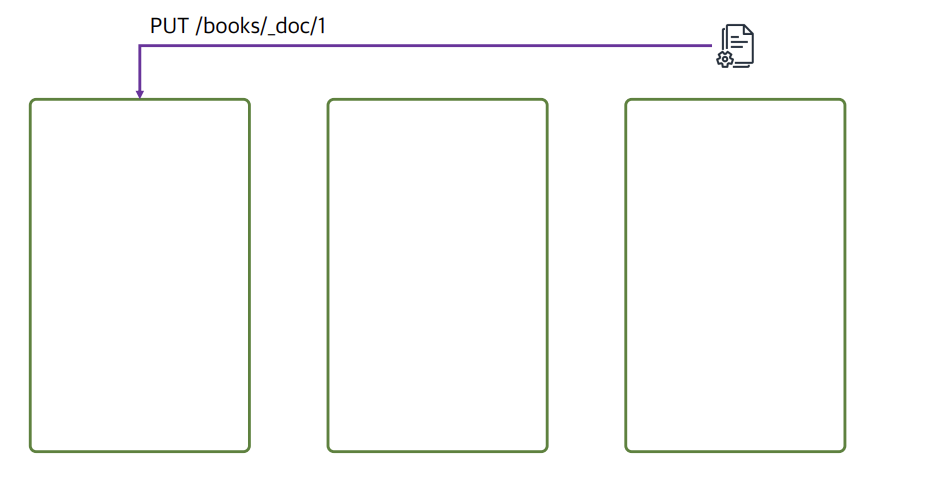
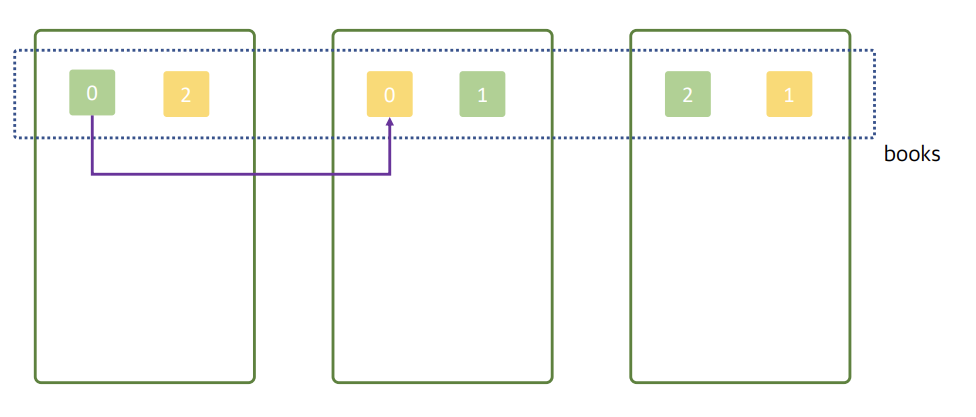
3개의 프라이머리 샤드(초록색)가 생성이 된다.
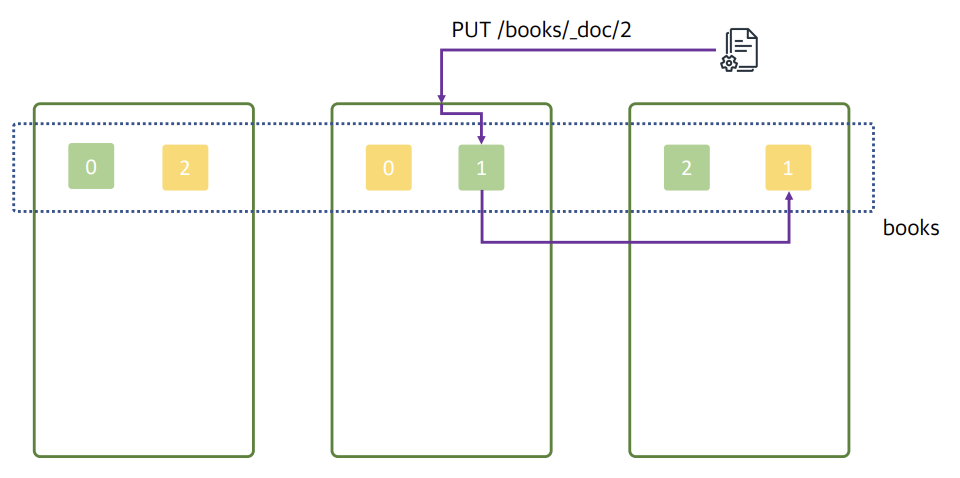
두번재 문서에 요청이 들어오면 해당 데이터노드에 있는 레플리카 샤드 1번 샤드에 들어가고 해당 번호와 동일한 세번재 데이터 노드에 존재하는 레플리카 샤드에 데이터를 복제한다.
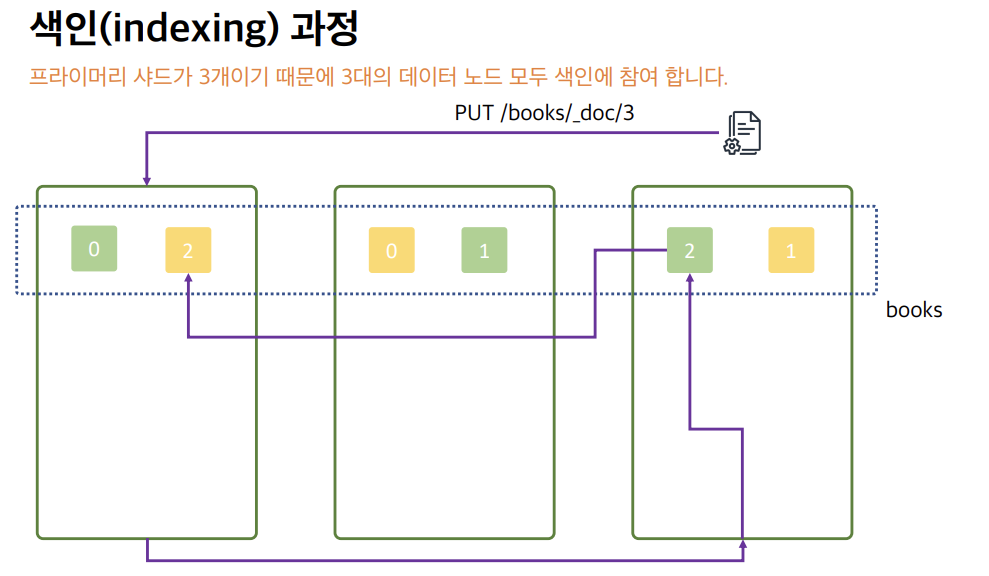
PUT /books/_doc/3 이와같이 색인 요청이 들어온다면, 해싱 알고리즘을 통해 처리되어, 세번째 데이터노드에있는 프라이머리 샤드로 전송되고 저장되게 된다. 그렇기에 2번 프라이머리 샤드에 데이터가 저장이 되고 그에 해당하는 2번 레플리카 샤드로 데이터를 복제하게 된다.
이렇게 된다면 데이터노드가 3대이고 해당 데이터노드들을 모두 사용하고 있다.하지만 여기서 데이터노드가 만약 하나 더 추가된다면?
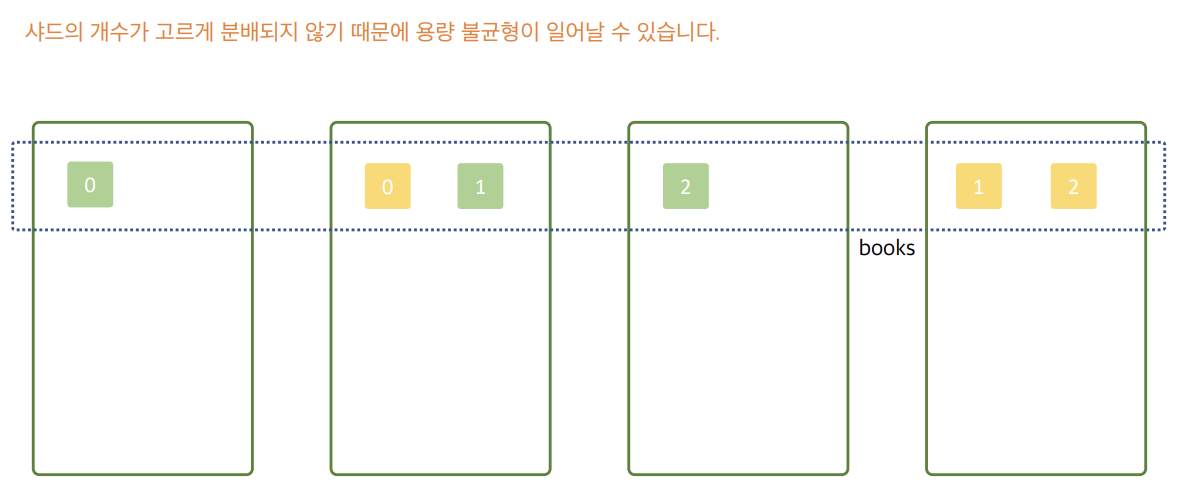
그림의 경우 네번째 데이터 노드가 추가되었다. 여기서 여전히 프라이머리 샤드는 3개이다.
이러한 경우 4개의 데이터 노드 중 3개의 노드만 프라이머리 샤드를 보유하게 됩니다.처음부터 완벽한 샤드 배치 계획을 세우기는 사실상 힘들다. 사용하면서 맞춰가는 형식을 추천한다.
추가로 개인적으로 궁금하였던 부분 - 레플리카 샤드 배치의 기본 원칙은?
1. 레플리카 샤드 배치의 기본 원칙
- 프라이머리 샤드와 같은 노드에 레플리카 샤드는 배치되지 않습니다.
- 이는 데이터 복구와 내결함성을 보장하기 위해 필수적인 규칙입니다. 만약 프라이머리 샤드와 레플리카 샤드가 같은 노드에 있다면, 해당 노드가 장애를 일으킬 경우, 데이터 손실이 발생할 수 있습니다.
- 레플리카 샤드는 프라이머리 샤드가 없는 다른 노드에 배치됩니다.
- 이로 인해 다른 노드에서 프라이머리 샤드에 문제가 생겼을 때, 레플리카 샤드를 이용해 데이터를 복구할 수 있게 됩니다.
2. 레플리카 샤드의 배치 과정
Elasticsearch는 다음과 같은 자동 샤드 할당 정책을 사용하여 레플리카 샤드를 배치합니다:
- 프라이머리 샤드가 없는 노드에 배치:
- 레플리카 샤드는 해당 프라이머리 샤드가 없는 노드에 자동으로 배치됩니다. 예를 들어, 프라이머리 샤드가 첫 번째 노드에 있으면, 레플리카 샤드는 두 번째, 세 번째, 네 번째 노드 중 하나에 배치됩니다.
- 균등한 부하 분산:
- Elasticsearch는 클러스터의 각 노드에 부하를 고르게 분산하려고 합니다. 따라서, 프라이머리 샤드와 레플리카 샤드가 가능한 한 여러 노드에 고르게 분산되도록 노력합니다. 예를 들어, 3개의 프라이머리 샤드와 3개의 레플리카 샤드가 있을 경우, 각 노드에 샤드가 균등하게 분배되도록 자동으로 조정됩니다.
- 추가적인 노드가 있는 경우:
- 만약 새로운 데이터 노드가 추가된다면, Elasticsearch는 자동으로 샤드를 재분배하여 새로운 노드에도 레플리카 샤드가 할당될 수 있도록 조정할 수 있습니다.
3. 실제 배치 예시
현재 4개의 데이터 노드가 있고 3개의 프라이머리 샤드와 3개의 레플리카 샤드가 있다고 가정하면, 다음과 같은 방식으로 샤드가 배치됩니다:
- 첫 번째 노드: 프라이머리 샤드 0, 레플리카 샤드 2
- 두 번째 노드: 프라이머리 샤드 1, 레플리카 샤드 0
- 세 번째 노드: 프라이머리 샤드 2, 레플리카 샤드 1
- 네 번째 노드: 아직 프라이머리 샤드가 없지만, 레플리카 샤드 2가 배치될 수 있습니다.
이 예시에서는 모든 샤드가 각 노드에 고르게 분배되어, 프라이머리와 레플리카 샤드가 동일한 노드에 존재하지 않도록 자동으로 조정됩니다.
반응형'ElasticSearch' 카테고리의 다른 글
ElasticSearch - text, keyword 대체 무엇이 다른가? (0) 2024.09.25 ElasticSearch - 검색과정 (0) 2024.09.24 ElasticSearch - 매핑(mapping) (0) 2024.09.22 ElasticSearch - 인덱스와 샤드 (0) 2024.09.22 Docker로 Kibana ElasticSearch 설치 후 연동 (0) 2024.09.19 - 프라이머리 샤드와 같은 노드에 레플리카 샤드는 배치되지 않습니다.
